Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap

Core idea
We study the real-to-simulated data gap in autonomous driving, specifically how models trained on real data perceive NeRF-rendered data. We find that there is a notable drop in performance for multiple perception models on images produced by a SOTA neural rendering method
Abstract
Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
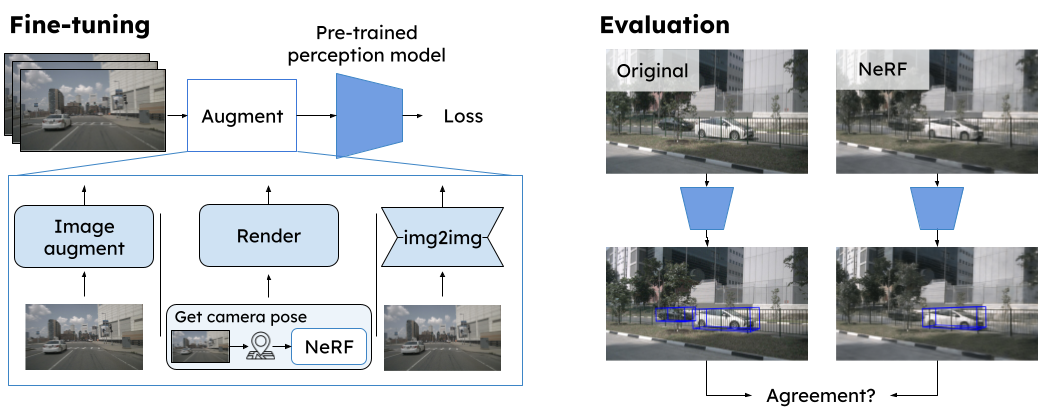
Method
To reduce the real2sim gap, we propose to make perception models more robust toward NeRF artifacts. Given already trained models, we fine-tune them on 3 different types of augmentations: hand-crafted image augmentations, NeRF-data, and img2img methods. As training NeRFs on many sequences is expensive, we do so only for a subset of the data. For this subset, we also train a img2img model




Results
We evaluate three 3D object detectors
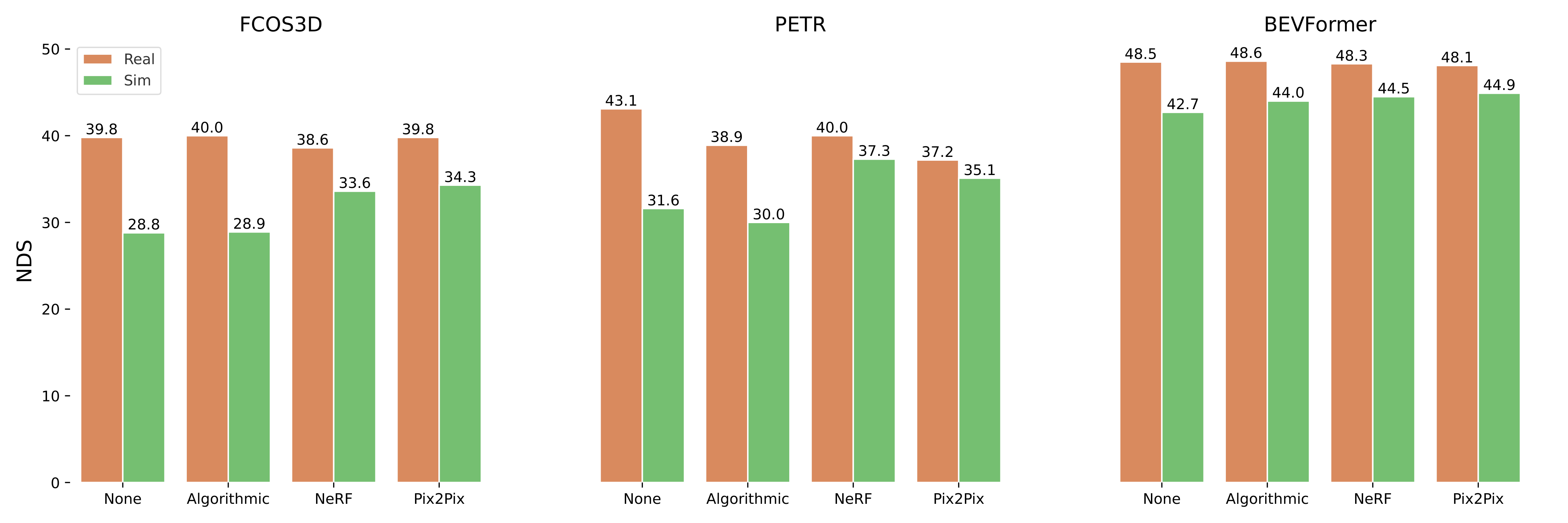
3D Object Detection
Below, we show nuScenes detection score (NDS) for the 3D object detectors trained on real data, fine-tuned with different augmentations, and evaluated on both real and simulated data. We see that all models improve on the NeRF data after fine-tuning. For both FCOS3D and BEVFormer, the img2img method can reduce the real2sim gap beyond simply adding NeRF data to the fine-tuning.
Online mapping
The video below shows the performance of the online mapping model on real data, NeRF-data from the same view point, and NeRF-data when rotating the ego-vehicle by different amounts (ccw=counterclockwise, cw=clockwise). The left video shows how predictions degrade as the rotation increases, even though the model has been fine-tuned with NeRF data. While the poor performance to some degree can be attributed to worse rendering quality, we also theorize that these types of scenes, with a large attack angle toward lane-markers, are rare in the perception model training data. Thus, we further fine-tune the model with rotated images (right), which significantly improves the performance on rotated NeRF data.
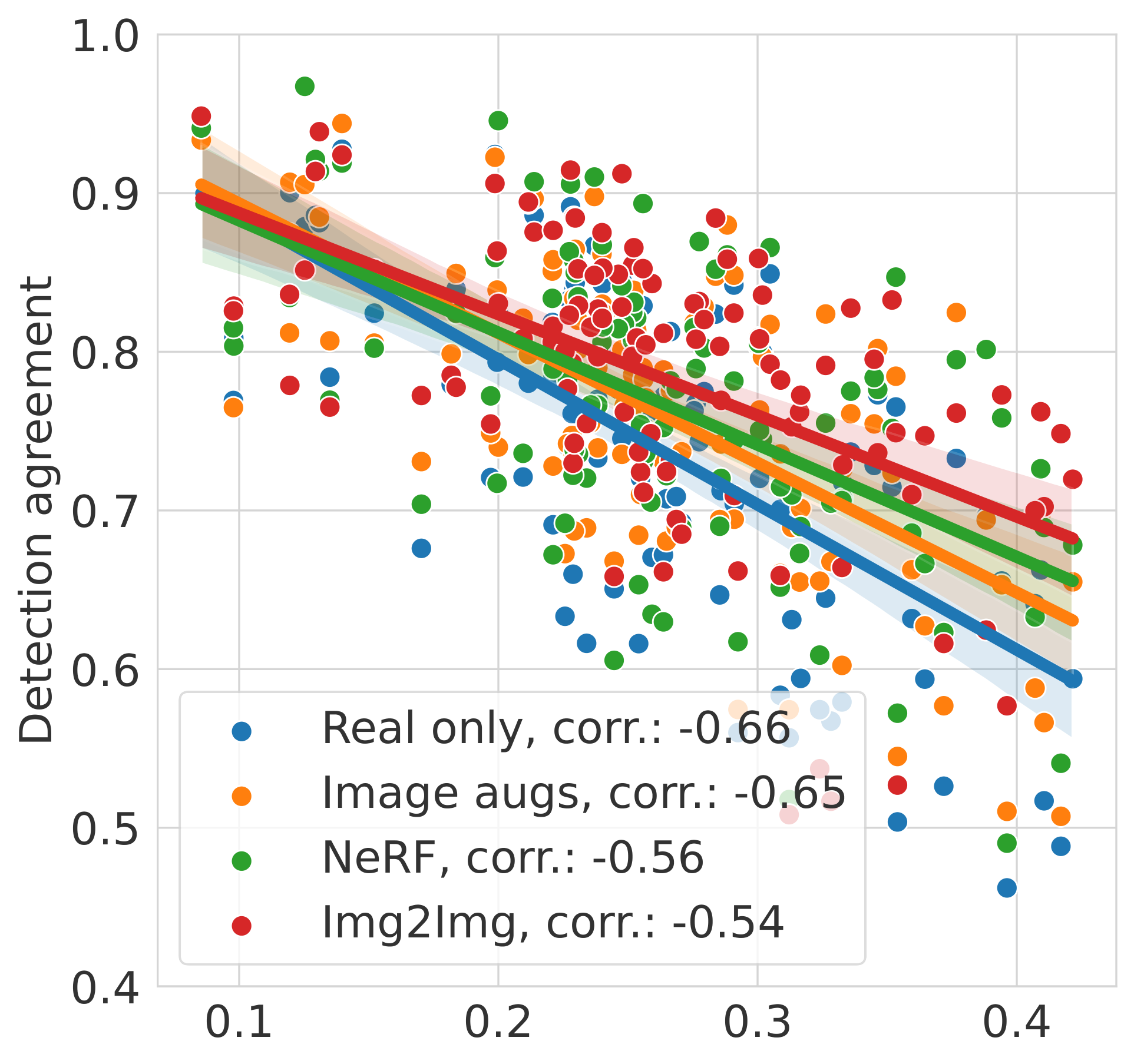
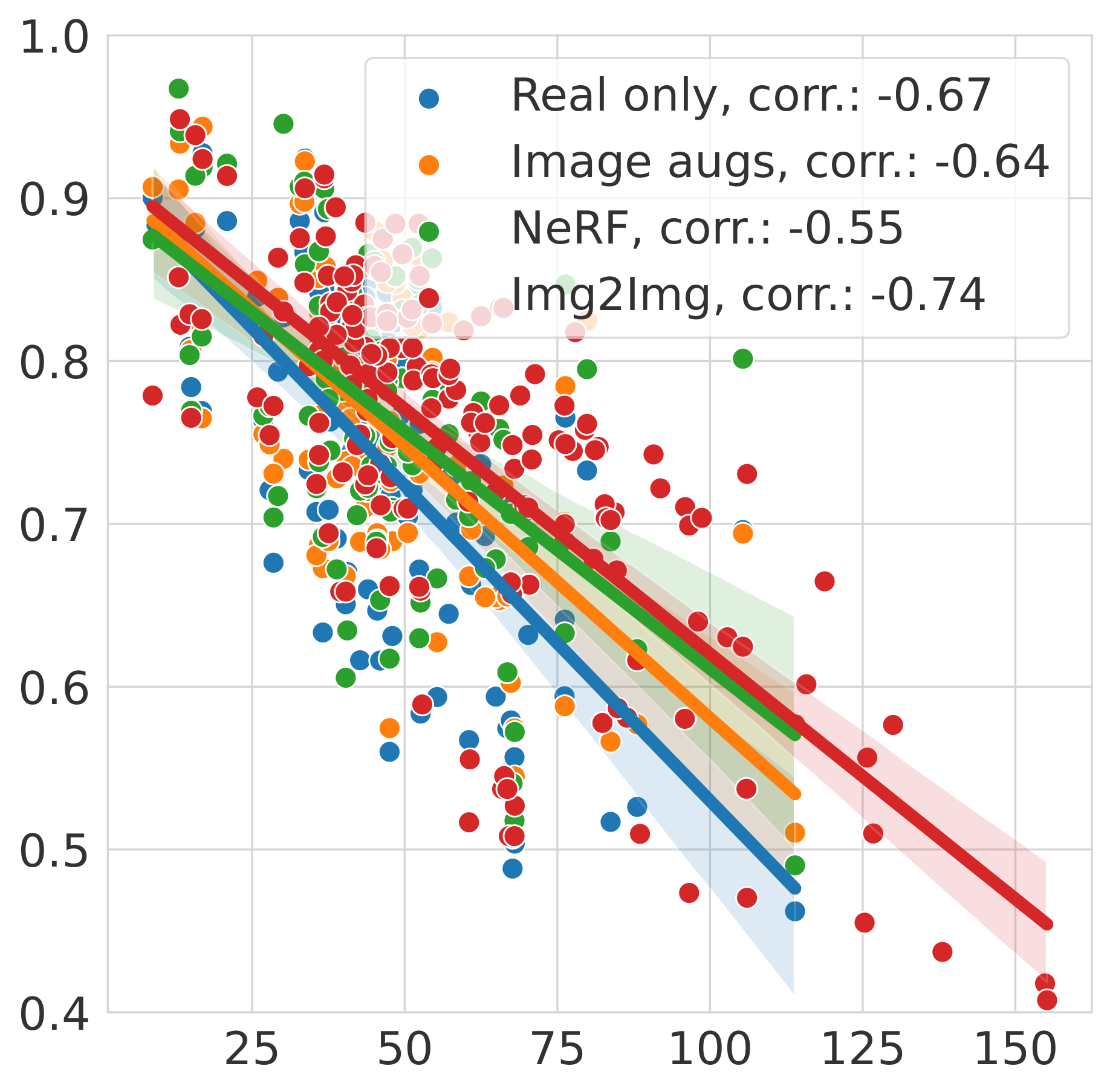
NVS metrics vs. real2sim gap
We find that the real2sim gap (defined as detection agreement between predictions on real vs NeRF data) correlates well with the FID and LPIPS metrics. The figure below shows the correlation between the real2sim gap and the FID and LPIPS metric for the object detectors, for different fine-tuning methods. This indicates that such learned perceptual metrics can be used as a proxy to evaluate the real2sim gap. Further, we see that our proposed fine-tuning methods mainly increase detection agreement when rendering quality is low (high FID and LPIPS).
BibTeX
@inproceedings{lindstrom2024real2sim,
title={Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap},
author={Lindstr{\"o}m, Carl and Hess, Georg and Lilja, Adam and Fatemi, Maryam and Hammarstrand, Lars and Petersson, Christoffer and Svensson, Lennart},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4461--4471},
year={2024}
}