Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
Abstract
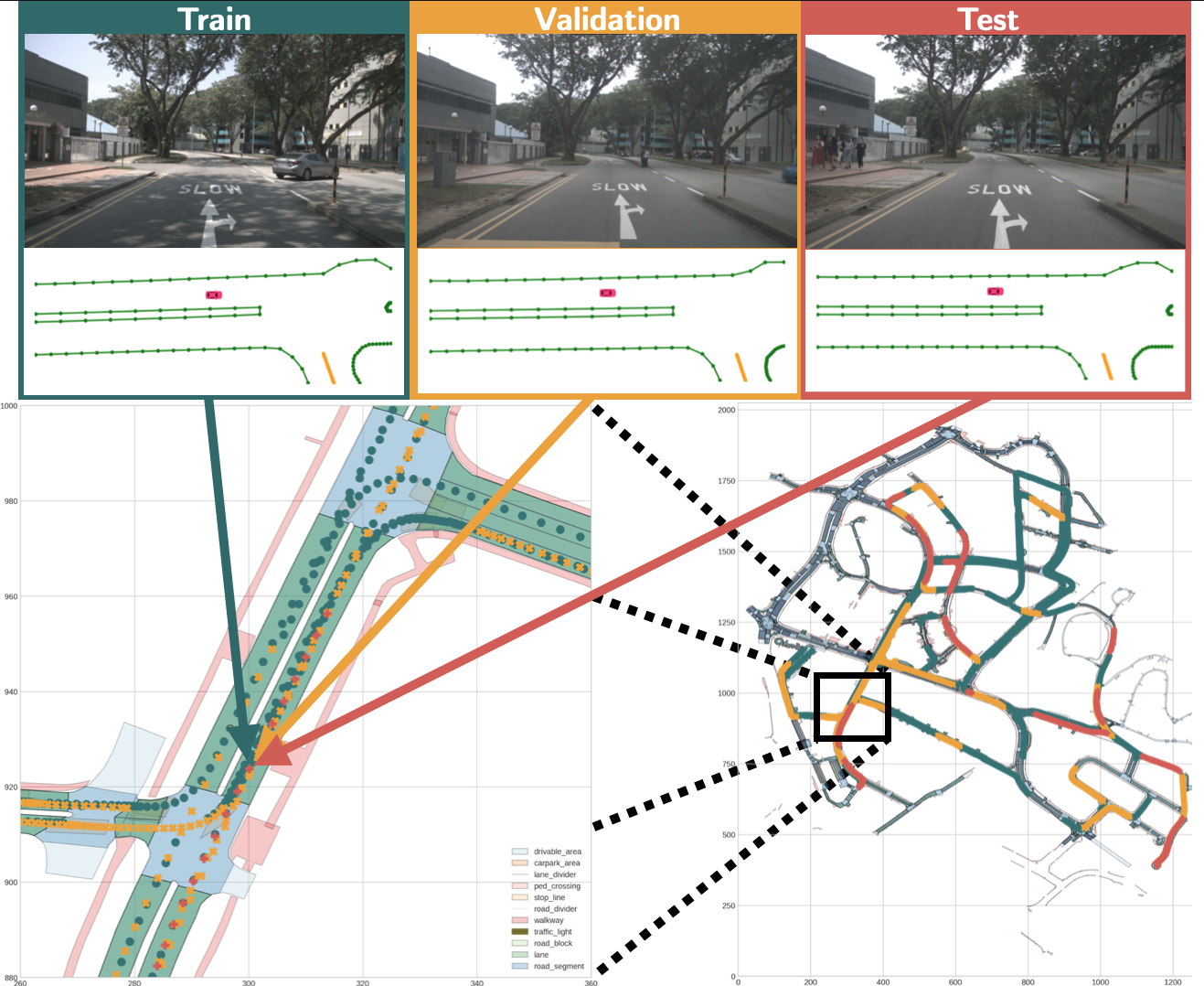
Having data leakage when training and evaluating any method based on supervised learning is a critical shortcoming. The state-of-the-art methods for online mapping are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. These datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over 80% of nuScenes and 60% of Argoverse 2 validation and test samples are located less than 5m from a training sample. This allows methods to localize within a memorized implicit map during testing, which in turn leads to inflated performance numbers being reported. To reveal the true performance in unseen environments, we introduce geographical splits of the data. Experimental results show significantly lower performance numbers, for some methods dropping with more than 45 mAP, when retraining and reevaluating existing online mapping models with the proposed split. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of the lifting method and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived.