Raw or Cooked? Object detection on RAW images
TL;DR
We propose doing object detection from RAW images, rather than from RGB images. We propose a learnable non-linearity, inspired by a transformation that seeks to improve the normality of the data, that is applied to the RAW image before it is fed to the object detector. We show that this quantitatively improves performance, compared to the traditional RGB pipeline, on the PASCALRAW dataset and qualitatively we observe that the RAW object detector tends to perform better in poor lighting conditions.
Basic idea
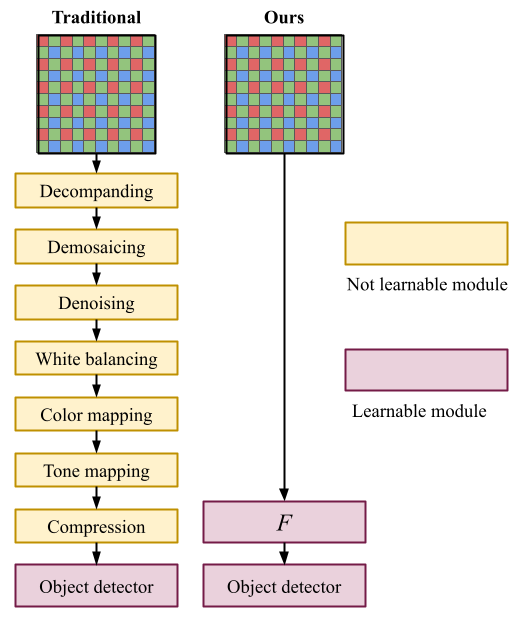
Generally, when working with computer vision, and deep neural networks, in particular, we start from the familiar RGB image. This is what people tend to consider to be the raw camera data, however, this is somewhat incorrect. To obtain the RGB image, the RAW camera data has undergone several handcrafted image signal processing (ISP) operations, all of which have been optimized to produce visually pleasing images. What we investigate in this work is whether this intermediate representation, the visually pleasing RGB image, is the best representation for the task at hand. Intuitively, the idea that a handcrafted representation is sub-optimal and that we can obtain superior performance by letting the optimization of the representation be guided by the end task seems reasonable. In summary, we want to replace the traditional pipeline, with a learnable pipeline defined by a learnable operation \(F(\mathbf{x})\).
Background on ISPs
As I mentioned above, the very familiar RGB image is actually not the RAW camera data, but rather a result of processing the actual RAW camera data into a representation that is visually pleasing for us as humans. The RAW camera data generally look more like what you can see on the left in Figure 2, an interleaved pattern of red, green, and blue filters. This is what is referred to as Bayer filter pattern, and while there are other configurations of color filters, the Bayer pattern is considered the most common.
In the ISP pipeline, the RAW data is processed sequentially by handcrafted operations. Even though an ISP can comprise any combination of operations, a common set of operations include demosaicing, denoising, white balancing, and tone mapping. An overview of a common ISP pipeline is shown in Figure 2.

Learnable operations
We study several different learnable operations \(F(\mathbf{x})\) that can be applied to the RAW image before it is fed to the object detector, all of which are outlined in slight detail below.
Learnable gamma correction.
Previous works
where \(\mathbf{x_d}\) is the demosaiced RAW image and \(\gamma\) is the learnable parameter optimized during training.
Learnable error function. The Learnable Gamma Correction still comprises two sequential operations (demosaicing and gamma correction). One can think of even more simple operations, such as a single non-linearity, that might be able to capture the same information. To this end, we adopt the Gauss error function and define learnable shift and scaling parameters to obtain a learnable error function as
\[F_{\text{erf}}(\mathbf{x}) = \text{erf} \left( \frac{\mathbf{x} - \mu}{\sqrt{2}\sigma} \right),\]where \(\mu\) and \(\sigma\) are learnable parameters optimized during training.
Learnable Yeo-Johnson transformation.
Lastly, by observing that the RAW data was far from normally distributed and knowing the fact that this is a characteristic that tends to improve the performance of deep neural networks, we sought to find a transformation that would make the RAW data more normally distributed. To this end, we adopt the Yeo-Johnson transformation
where \(\lambda\) is a learnable parameter optimized during training.
Results
To evaluate the effect our proposed learnable operations have on downstream computer vision tasks, we employ an object detection setting. Here, we make use of the PASCALRAW dataset, which comprises RAW and RGB images, as well as 2D bounding box annotations for cars, pedestrians, and bicycles.
We adopt a Faster R-CNN
Qualitative results. We evaluated our three pipelines separately, and compared them to two baselines:
- RGB baseline. This is the traditional object detection pipeline, where we feed the RGB image directly into the object detector.
- Naïve baseline. Here, we feed the RAW image directly into the object detector, without any learnable operations. In other words letting \(F(\mathbf{x}) = \mathbf{x}\).
In Table 1 we present the quantitative results for each of our learnable operations and the baselines. Here, the results are presented as mean and standard deviation across three seperate runs. As you can see, our RAW + Learnable Yeo-Johnson detector outperforms both the RGB and naïve baselines, as well as the other learnable operations, with some margin.

Quantitative results. In Figure 4 below you see three examples from the PASCALRAW dataset. We show the ground truth bounding boxes in the top row, RGB baseline detections in the center, and RAW + Yeo-Johnson detections in the bottom row. We observe that the RAW + Yeo-Johnson detector tends to perform better in low-light conditions, compared to the RGB baseline detector, but also that they have similar performance in well-lit conditions.

Concluding remarks
Motivated by the observation that camera ISP pipelines are typically optimized toward producing visually pleasing images for the human eye, we have in this work experimented with object detection on RAW images. While naïvely feeding RAW images directly into the object detection backbone led to poor performance, we proposed three simple, learnable operations that all led to good performance. Two of these operators, the Learnable Gamma and Learnable Yeo-Johnson, led to superior performance compared to the RGB baseline detector. Based on qualitative comparison, the RAW detector performs better in low-light conditions compared to the RGB detector.
BibTeX
@inproceedings{ljungbergh2023raw,
title = {Raw or cooked? Object detection on RAW images},
author = {Ljungbergh, William and Johnander, Joakim and Petersson, Christoffer and Felsberg, Michael},
booktitle = {Scandinavian Conference on Image Analysis},
pages = {374--385},
year = {2023},
organization = {Springer}
}