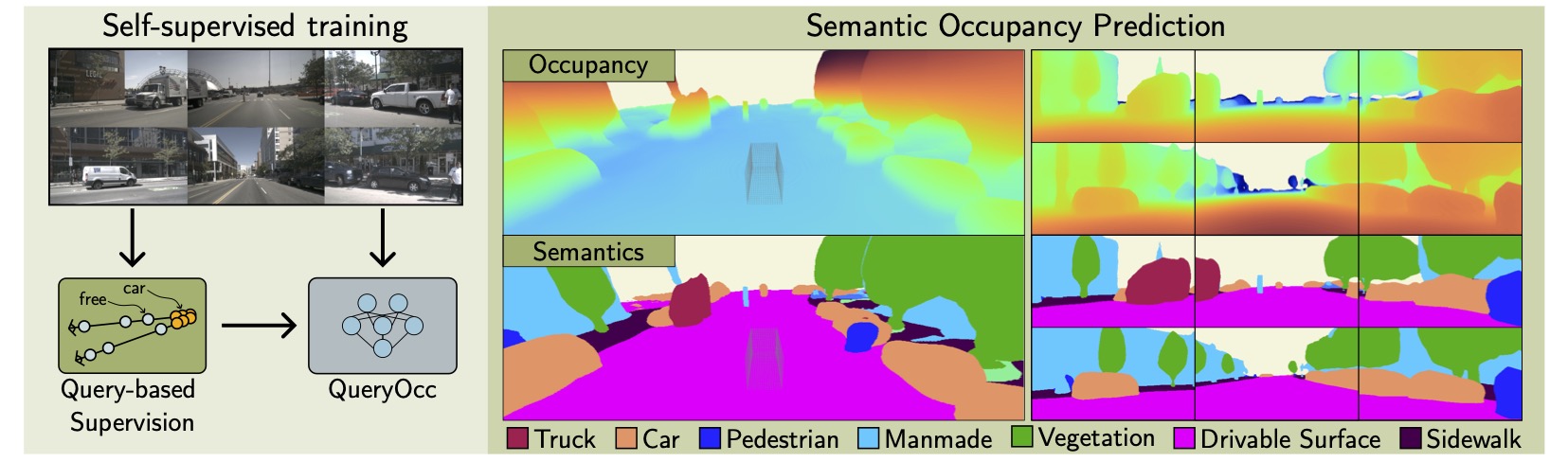
QueryOcc: Query-based Self-Supervision for 3D Semantic Occupancy

TLDR: QueryOcc
Query-based self-supervised framework that learns continuous 3D semantic occupancy directly through independent 4D spatio-temporal queries sampled across adjacent frames. The framework supports supervision from either pseudo-point clouds derived from vision foundation models or raw lidar data. To enable long-range supervision and reasoning under constant memory, we introduce a contractive scene representation that preserves near-field detail while smoothly compressing distant regions.

Method
QueryOcc predicts whether any 3D point in the scene is occupied and its semantic class — directly from multi-view images, without ever building a fixed voxel grid. The model takes a 4D query and a set of calibrated images, and outputs an occupancy probability and a distribution over semantic classes for that exact point.
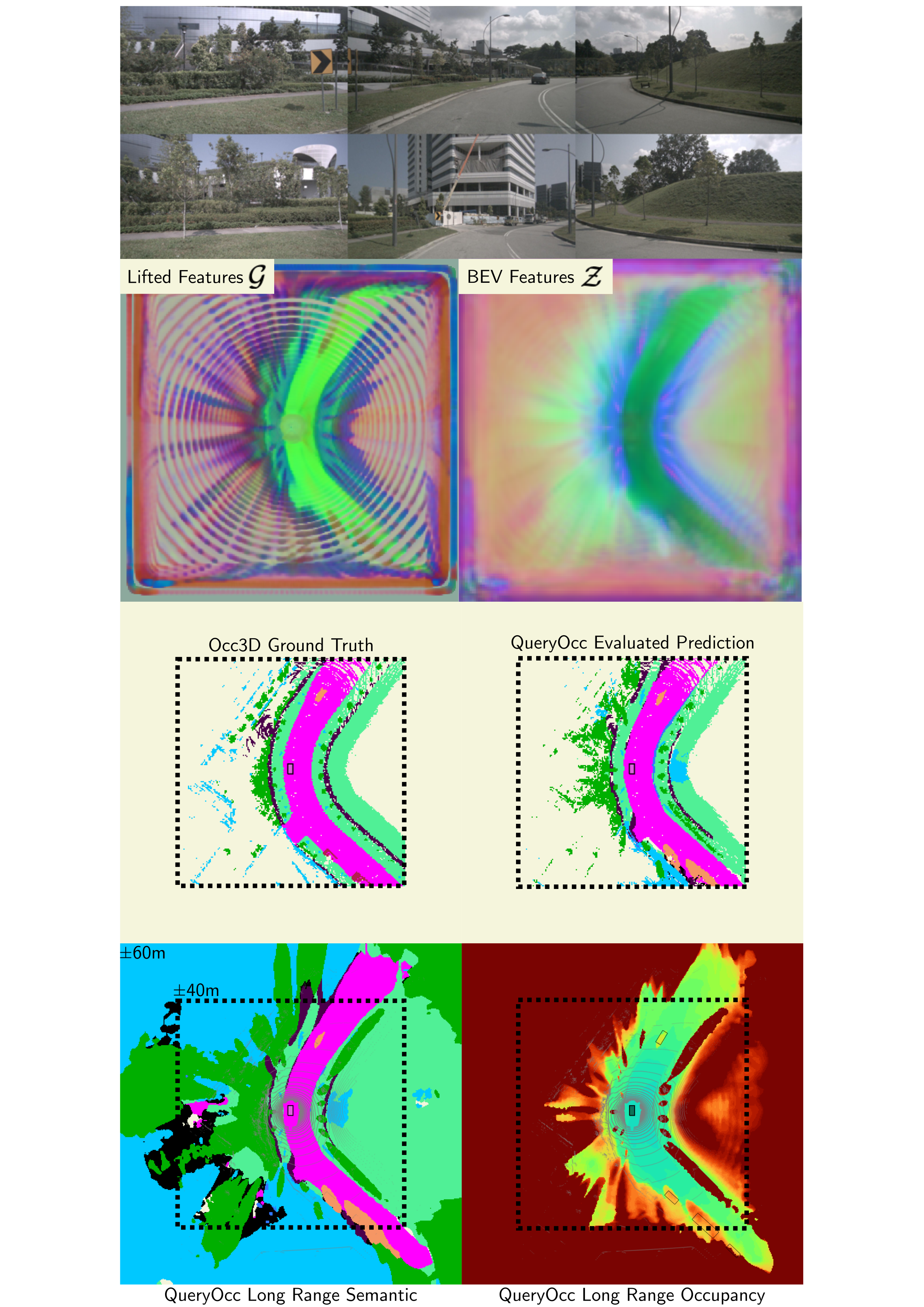
The pipeline has four stages: (1) a standard image encoder extracts per-view features, (2) a Lift–Contract–Splat module lifts them into a BEV representation, (3) ResBlocks and deformable attention process the BEV features, and (4) a lightweight decoder answers arbitrary 4D queries from the resulting feature map.

Self-Supervised Training
QueryOcc is trained without any manual 3D labels. Supervision comes entirely from observations at adjacent timesteps: the model must correctly predict occupancy and semantics at 4D queries derived from those frames.
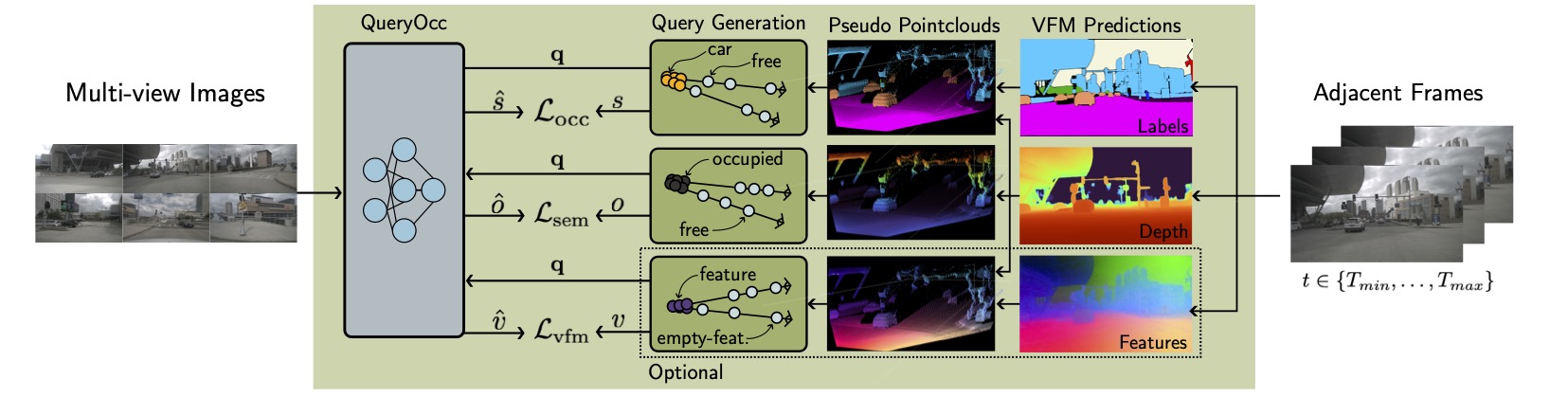
Point clouds are obtained from either images or lidar. In the camera-only setup (QueryOcc), metric depth from an off-the-shelf depth model lifts pixels into pseudo point clouds, paired with semantic pseudo-labels or dense vision foundation model (VFM) features. If lidar is available, observed point clouds can replace or augment the pseudo points — this extended setup is QueryOcc+.
From any point cloud, supervision is generated as a set of 4D queries sampled along sensor rays. Negative (unoccupied) queries are placed between the sensor origin and each surface point; positive (occupied) queries are placed just behind it. The model is trained with binary cross-entropy for occupancy, cross-entropy for semantics, and L1 for optional VFM feature distillation — all without ever discretizing the scene into a fixed voxel grid.
Results
QueryOcc sets a new state of the art among self-supervised camera-based methods on Occ3D-nuScenes, surpassing all prior work across both semantic and geometric metrics — while running at 11.6 FPS.
| Method | RayIoU ↑ | IoU ↑ | ||||
|---|---|---|---|---|---|---|
| Sem. | Dyn. | Occ. | Sem. | Dyn. | Occ. | |
| SelfOcc† | 10.9 | 7.2 | 29.2 | 10.5 | 3.7 | 45.0 |
| OccNeRF | — | — | — | 10.8 | 3.7 | 22.8 |
| DistillNeRF | — | — | — | 10.1 | 5.2 | 29.1 |
| LangOcc† | 11.6 | 9.0 | 38.7 | 13.3 | 7.7 | 51.8 |
| GaussianOcc | 11.9 | — | — | 11.3 | 7.0 | — |
| MinkOcc w/lidar | 12.5 | — | — | 13.2 | 3.4 | — |
| GaussTR† FeatUp | 13.8 | 14.5 | 34.2 | 13.3 | 9.0 | 45.2 |
| GaussTR† T2D | 14.2 | 17.7 | 33.8 | 13.9 | 13.4 | 44.5 |
| GaussianFlowOcc | 18.7 | — | — | 17.1 | 10.1 | 46.9 |
| GaussianFlowOcc* | 18.2 | 17.2 | 36.0 | 16.1 | 9.9 | 40.2 |
| QueryOcc | 23.6 | 21.7 | 45.2 | 21.3 | 13.2 | 55.0 |
| QueryOcc+ | 25.8 | 23.8 | 47.4 | 23.5 | 15.7 | 56.9 |
† RayIoU reproduced · * Both metrics reproduced · 1st 2nd 3rd among comparable methods.
| Model | Mean | Barrier | Bicycle | Bus | Car | Cons. veh. | Drive. surf. | Manmade | Motorcycle | Pedestrian | Sidewalk | Terrain | Traffic cone | Trailer | Truck | Vegetation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SelfOcc | 10.5 | 0.2 | 0.7 | 5.5 | 12.5 | 0.0 | 55.5 | 14.2 | 0.8 | 2.1 | 26.3 | 26.5 | 0.0 | 0.0 | 8.3 | 5.6 |
| OccNeRF | 10.8 | 0.8 | 0.8 | 5.1 | 12.5 | 3.5 | 52.6 | 18.5 | 0.2 | 3.1 | 20.8 | 24.8 | 1.8 | 0.5 | 3.9 | 13.2 |
| DistillNeRF | 10.1 | 1.4 | 2.1 | 10.2 | 10.1 | 2.6 | 43.0 | 14.1 | 2.0 | 5.5 | 16.9 | 15.0 | 4.6 | 1.4 | 7.9 | 15.1 |
| LangOcc | 13.3 | 3.1 | 9.0 | 6.3 | 14.2 | 0.4 | 43.7 | 19.6 | 10.8 | 6.2 | 9.5 | 26.4 | 9.0 | 3.8 | 10.7 | 26.4 |
| GaussianOcc | 11.3 | 1.8 | 5.8 | 14.6 | 13.6 | 1.3 | 44.6 | 8.6 | 2.8 | 8.0 | 20.1 | 17.6 | 9.8 | 0.6 | 9.6 | 10.3 |
| GaussTR FeatUp | 13.3 | 2.1 | 5.2 | 14.1 | 20.4 | 5.7 | 39.4 | 21.2 | 7.1 | 5.1 | 15.7 | 22.9 | 3.9 | 0.9 | 13.4 | 21.9 |
| GaussTR T2D | 13.9 | 6.5 | 8.5 | 21.8 | 24.3 | 6.3 | 37.0 | 21.2 | 15.5 | 7.9 | 17.2 | 7.2 | 1.9 | 6.1 | 17.2 | 10.0 |
| GaussianFlowOcc | 17.1 | 7.2 | 9.3 | 17.6 | 17.9 | 4.5 | 63.9 | 14.6 | 9.3 | 8.5 | 31.1 | 35.1 | 10.7 | 2.0 | 11.8 | 12.6 |
| QueryOcc | 21.3 | 7.3 | 6.8 | 26.5 | 20.9 | 4.8 | 69.2 | 25.2 | 10.9 | 15.0 | 34.5 | 38.4 | 13.2 | 3.7 | 17.3 | 25.7 |
| QueryOcc+ | 23.5 | 9.0 | 10.0 | 30.4 | 25.5 | 4.6 | 69.6 | 28.0 | 16.5 | 17.0 | 37.2 | 42.4 | 11.8 | 3.4 | 18.5 | 28.8 |
Per-class IoU ↑ on Occ3D-nuScenes. 1st 2nd 3rd among comparable methods.
Qualitative Examples
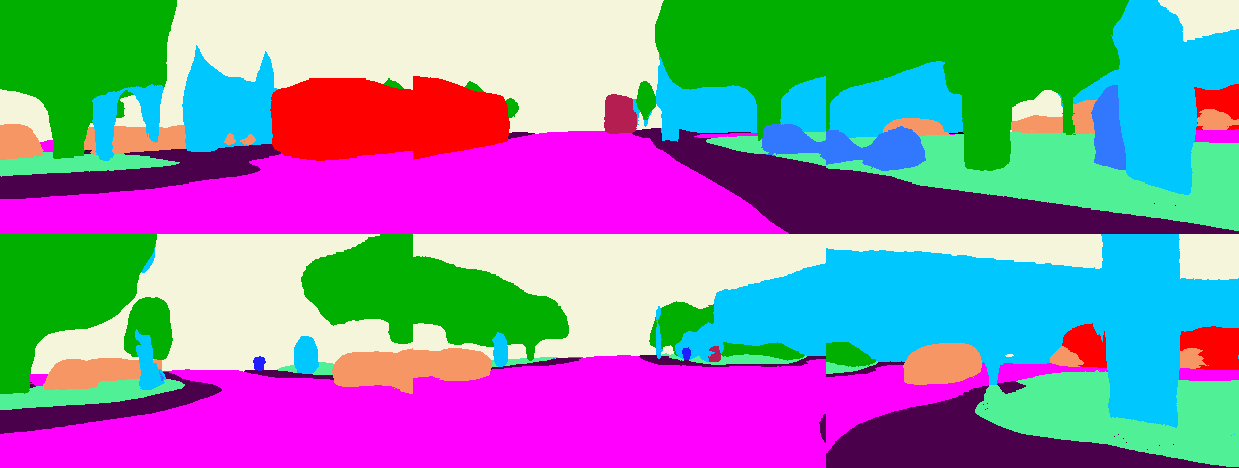
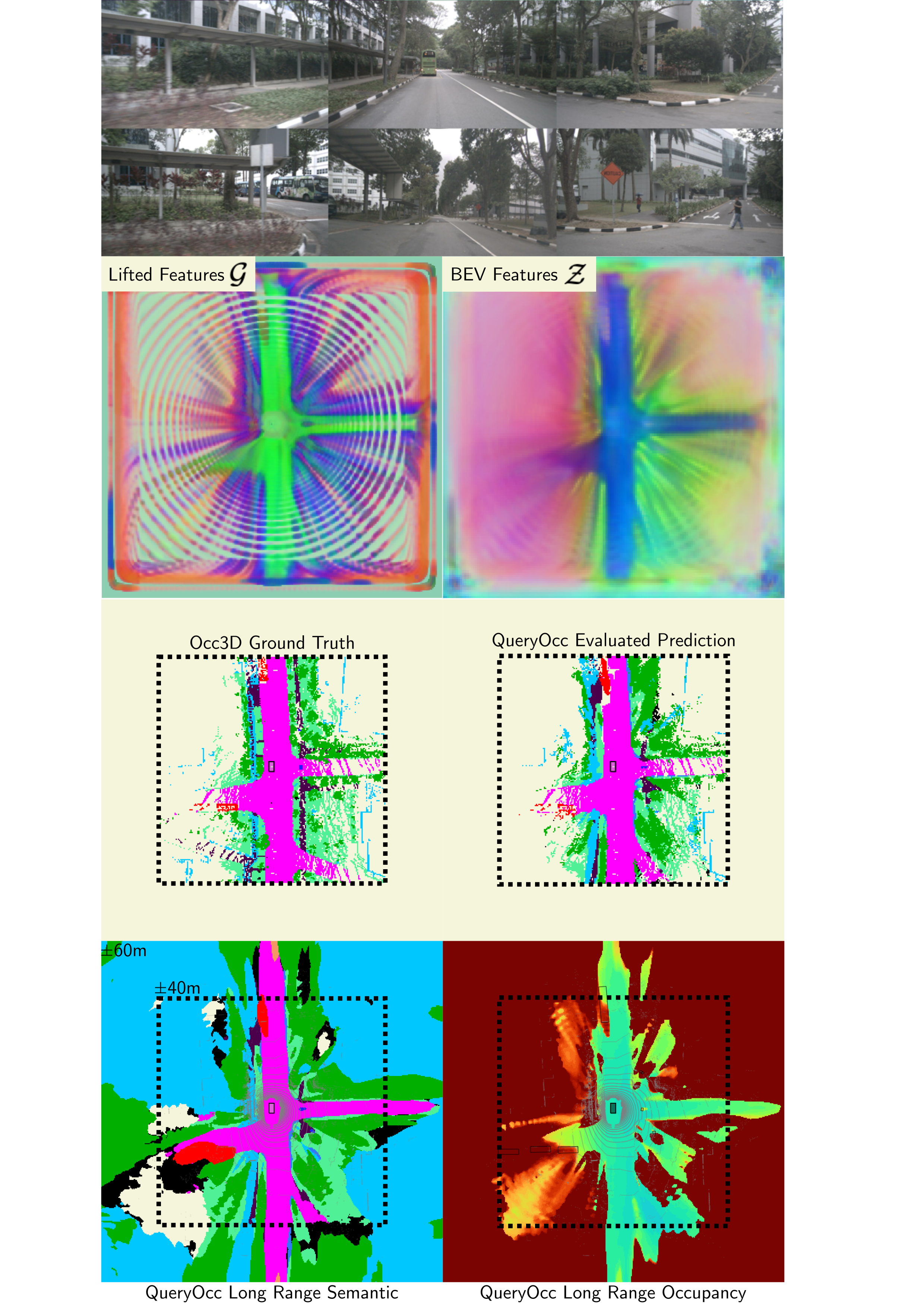
QueryOcc produces sharp geometry, maintains fine-grained detail, and infers plausible structures behind occlusions.



Long-range predictions — Extending visualization from ±40 m to ±60 m shows that the contracted BEV preserves useful geometric signal well beyond the evaluation boundary.
BibTeX
@article{lilja2026queryocc,
title = {QueryOcc: Query-based Self-Supervision for 3D Semantic Occupancy},
author = {Adam Lilja and Ji Lan and Junsheng Fu and Lars Hammarstrand},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2026}
}